best-practices
This page collects best practices related to high availability Namespaces.
- Preparing Worker deployment
- Set up secure routing for failovers
- PrivateLink routing
- High availability Failover testing
- Monitoring replication lag metrics
- Viewing operational events
High availability Failover testing
Regular failover testing ensures your app can handle disruptions and continue running smoothly in production.
Microservices and external dependencies will fail at some point. Testing failovers ensures your app can handle these failures effectively.
Temporal recommends regular and periodic failover testing for mission-critical applications in production. By testing in non-emergency conditions, you verify that your app continues to function even when parts of the infrastructure fail.
If this is your first time performing a failover test, run it with a test-specific namespace and application. This helps you gain operational experience before applying it to your production environment. Practice runs help ensure the process runs smoothly during real incidents in production.
Trigger testing can:
-
Validate high-availability deployments: In multi-region setups, failover testing ensures your app can run from another region when the primary region experiences outages. In single-region setups, failover testing instead works with isolation domain. This maintains high availability in mission-critical deployments. Manual testing confirms the failover mechanism works as expected, so your system handles incidents effectively.
-
Assess replication lag: In multi-region deployment, monitoring replication lag between regions is crucial. Check the lag before initiating a failover to avoid rolling back Workflow progress. This is less important when using isolation domains as failover is usually instantaneous. Manual testing helps you practice this critical step and understand its impact. When there's no real incident, the switch over (recovery) should happen almost instantly. A switch over within a single region should also be nearly instantaneous.
-
Assess recovery time: Manual testing helps you measure actual recovery time. You can check if it meets your expected Recovery Time Objective (RTO) of 20 minutes or less, as stated in the High availability Namespace SLA.
-
Identify potential issues: Failover testing uncovers problems not visible during normal operation. This includes issues like backlogs and capacity planning and how external dependencies behave during a failover event.
-
Validate fault-oblivious programming: Temporal uses a "fault-oblivious programming" model, where your app doesn’t need to explicitly handle many types of failures. Testing failovers ensures that this model works as expected in your app.
-
Operational readiness: Regular testing familiarizes your team with the failover process, improving their ability to handle real incidents when they arise.
Testing failovers regularly ensures your Temporal-based applications remain resilient and reliable, even when infrastructure fails.
Preparing Worker deployment
Enabling high availability for Namespaces doesn't require specific Worker configuration. The process is invisible to the Workers. When a Namespace fails over to the replica, the DNS redirection orchestrated by Temporal ensures that your existing Workers continue to poll the Namespace without interruption. More details are available in the Routing section.
-
When a Namespace fails over to a replica in a different region, Workers will be communicating cross-region. If your application can’t tolerate this latency, deploy a second set of Workers in this region or opt for a replica in the same region.
-
In case of a complete regional outage, Workers in the original region may fail alongside the original Namespace. To keep Workflows moving during this level of outage, deploy a second set of Workers to the secondary region.
Set up secure routing for failovers
When using a high availability Namespace, the Namespace's DNS record <ns>.<acct>.<tmprl_domain> targets a regional DNS record in the format <region>.region.<tmprl_domain>.
Here, <region> is the currently active region for your Namespace.
Clients resolving the Namespace’s DNS record are directed to connect to the active region for that Namespace, thanks to the regional DNS record.
During failover, Temporal Cloud changes the target of the Namespace DNS record from one region to another. Namespace DNS records are configured with a 15 seconds TTL. Any DNS cache should re-resolve the record within this delay. As a rule of thumb, DNS reconciliation takes no longer than twice (2x) the TTL. Clients should converge to the newly targeted region within, at, most a 30-second delay.
PrivateLink routing
Some networking configuration is required for failover to be transparent to clients and workers when using PrivateLink. This section describes how to configure routing for multi-region Namespaces for PrivateLink customers only.
PrivateLink customers may need to change certain configurations for multi-region Namespace use. Routing configuration depends on networking setup and use of PrivateLink. You may need to:
- override a DNS zone; and
- ensure the network connectivity between the two regions.
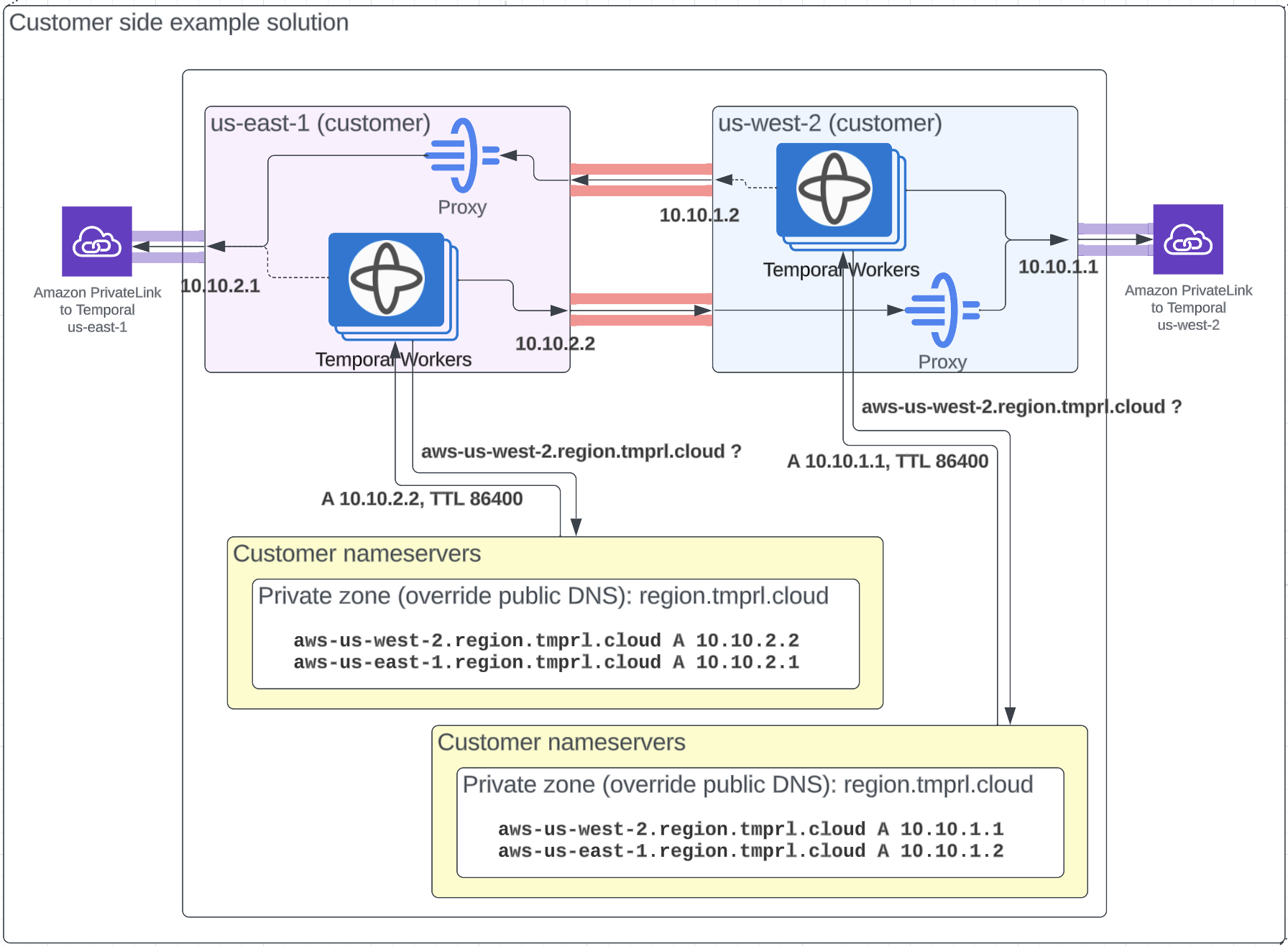
When using PrivateLink, you connect to Temporal Cloud using IP addresses local to your network.
The region.<tmprl_domain> zone is configured in the Temporal systems as an independent zone.
This allows you to override it to make sure traffic is routed internally for the regions in use.
You can check the Namespace's active region using the Namespace record CNAME, which is public.
To set up the DNS override, you override specific regions to target the relevant IP addresses (e.g. aws-us-west-1.region.tmprl.cloud to target 192.168.1.2).
Using AWS, this can be done using a private hosted zone in Route53 for region.<tmprl_domain>.
Link that private zone to the VPCs you use for Workers.
Private Link is not yet offered for GCP multi-region Namespaces.
When your Workers connect to the Namespace, they first resolve the <ns>.<acct>.<tmprl_domain> record.
This targets <active>.region.<tmprl_domain> using a CNAME.
Your private zone overrides that second DNS resolution, leading traffic to reach the internal IP you're using.
Consider how you'll configure Workers to run in this scenario. You might set Workers to run in both regions at all times. Alternately, you could establish connectivity between the regions to redirect Workers once failover occurs.
The following table lists Temporal's available regions, PrivateLink endpoints, and DNS record overrides.
The sa-east-1 region listed here is not yet available for use with multi-region Namespaces.
| Region | PrivateLink Service Name | DNS Record Override |
|---|---|---|
ap-northeast-1 | com.amazonaws.vpce.ap-northeast-1.vpce-svc-08f34c33f9fb8a48a | aws-ap-northeast-1.region.tmprl.cloud |
ap-northeast-2 | com.amazonaws.vpce.ap-northeast-2.vpce-svc-08c4d5445a5aad308 | aws-ap-northeast-2.region.tmprl.cloud |
ap-south-1 | com.amazonaws.vpce.ap-south-1.vpce-svc-0ad4f8ed56db15662 | aws-ap-south-1.region.tmprl.cloud |
ap-south-2 | com.amazonaws.vpce.ap-south-2.vpce-svc-08bcf602b646c69c1 | aws-ap-south-2.region.tmprl.cloud |
ap-southeast-1 | com.amazonaws.vpce.ap-southeast-1.vpce-svc-05c24096fa89b0ccd | aws-ap-southeast-1.region.tmprl.cloud |
ap-southeast-2 | com.amazonaws.vpce.ap-southeast-2.vpce-svc-0634f9628e3c15b08 | aws-ap-southeast-2.region.tmprl.cloud |
ca-central-1 | com.amazonaws.vpce.ca-central-1.vpce-svc-080a781925d0b1d9d | aws-ca-central-1.region.tmprl.cloud |
eu-central-1 | com.amazonaws.vpce.eu-central-1.vpce-svc-073a419b36663a0f3 | aws-eu-central-1.region.tmprl.cloud |
eu-west-1 | com.amazonaws.vpce.eu-west-1.vpce-svc-04388e89f3479b739 | aws-eu-west-1.region.tmprl.cloud |
eu-west-2 | com.amazonaws.vpce.eu-west-2.vpce-svc-0ac7f9f07e7fb5695 | aws-eu-west-2.region.tmprl.cloud |
sa-east-1 | com.amazonaws.vpce.sa-east-1.vpce-svc-0ca67a102f3ce525a | aws-sa-east-1.region.tmprl.cloud |
us-east-1 | com.amazonaws.vpce.us-east-1.vpce-svc-0822256b6575ea37f | aws-us-east-1.region.tmprl.cloud |
us-east-2 | com.amazonaws.vpce.us-east-2.vpce-svc-01b8dccfc6660d9d4 | aws-us-east-2.region.tmprl.cloud |
us-west-2 | com.amazonaws.vpce.us-west-2.vpce-svc-0f44b3d7302816b94 | aws-us-west-2.region.tmprl.cloud |
Monitoring replication lag metrics
Replication lag refers to the transmission delay of Workflow updates and history events from an active to a standby Namespace. A forced failover when there is a large replication lag has a higher likelihood of rolling back Workflow progress. Always check the metric replication lag before initiating a high availability failover, especially when working with multi-region deployment.
Temporal Cloud emits three replication lag-specific metrics.
temporal_cloud_v0_replication_lag_bucket: A histogram of replication lag during a specific time interval for a high availability Namespace.temporal_cloud_v0_replication_lag_count: The replication lag count during a specific time interval for a high availability Namespace.temporal_cloud_v0_replication_lag_sum: The sum of replication lag during a specific time interval for a high availability Namespace.
The following samples demonstrate how you can use these metrics to explore replication lag.
P99 replication lag histogram
histogram_quantile(0.99, sum(rate(temporal_cloud_v0_replication_lag_bucket[$__rate_interval])) by (temporal_namespace, le))
Average replication lag
sum(rate(temporal_cloud_v0_replication_lag_sum[$__rate_interval])) by (temporal_namespace)
/
sum(rate(temporal_cloud_v0_replication_lag_count[$__rate_interval])) by (temporal_namespace)
Viewing operational events
You can view and alert on key cloud metrics using the Web UI, the 'tcld' CLI utility, and Temporal Cloud APIs. For example, during the process of adding a region or isolation domain to a Namespace, you can see the progress of Workflow replication. Errors -- if any occur -- will also surface in the Namespace Web UI.
You may notice that high-availability Namespaces shows twice (2x) the Action count in temporal_cloud_v0_total_action_count.
This doubling happens due to regional replication.
Temporal Cloud provides several ways to audit events:
- When Temporal triggers failovers, the audit log updates with details.
Look specifically for
"operation": "FailoverNamespace"in the logs. - You can set alerts for Temporal-initiated failover events.
- After a failover, you can check that the Namespace is active in the new region using the Temporal Cloud Web UI.